连载之(2)美国斯坦福大学:2023 年 人工智能指数报告
原创 2023-04-21 13:27 南山 来源:AGV网1.2重要的机器学习系统的发展趋势
通用的机器学习系统
下面的数字报告了在Epoch数据集中包含的所有机器学习系统的趋势。作为参考,这些系统在整个小节中被称为重要的机器学习系统。
系统类型
在2022年发布的重要的人工智能机器学习系统中,最常见的系统类别是语言(图1.2.1)。2022年发布了23个重要的人工智能语言系统,大约是第二常见的系统类型——多模态系统的6倍。
2022年按领域划分的重要机器学习系统的数量
(资料来源: Epoch,2022年|图表: 2023年人工智能指数报告)
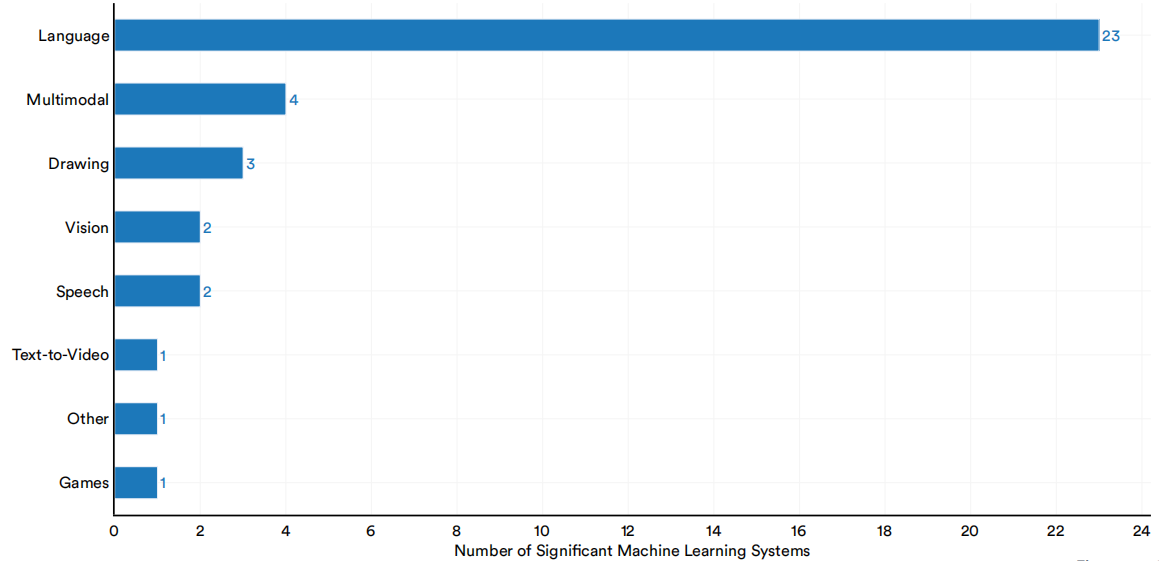
图1.2.1
行业分析
在工业界、学术界或非营利组织中,哪个部门发布了最多的重要的机器学习系统?直到2014年,大多数机器学习系统都是由学术界发布的。从那时起,行业就接管了公司(图1.2.2)。2022年,有32个重要的工业机器学习系统,而学术界生产的只有3个。生产最先进的人工智能系统越来越需要大量的数据、计算能力和资金;与非营利组织和学术界相比,行业参与者拥有更多的资源。
2002-22年重要机器学习系统的数量
(资料来源: Epoch,2022年|图表: 2023年人工智能指数报告)
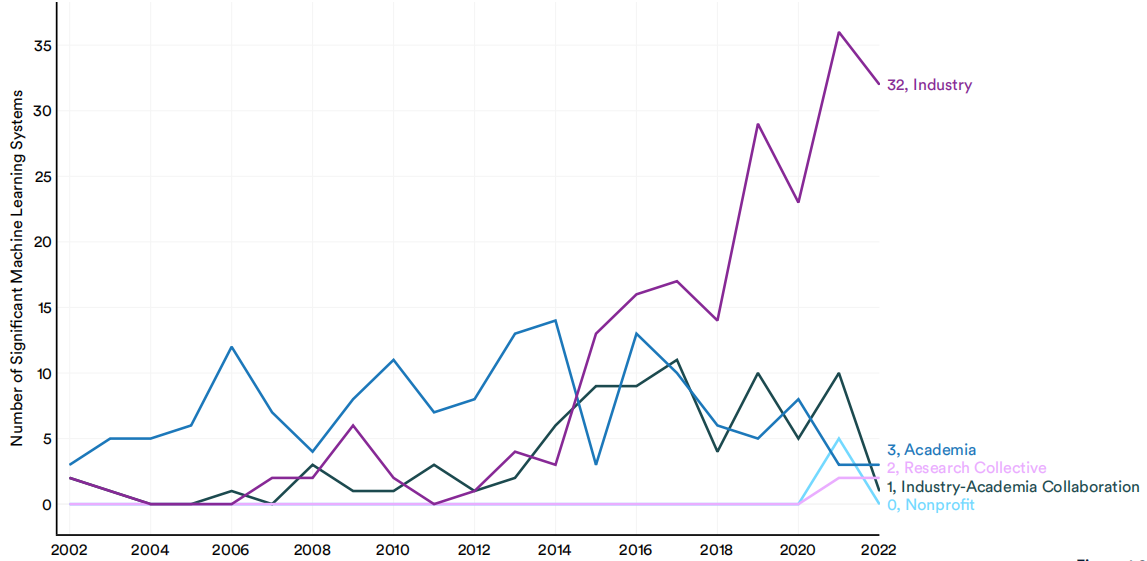
图1.2.2
国家关系
为了描绘一幅人工智能不断发展的地缘政治图景,人工智能指数研究团队确定了为Epoch数据集中每个重要机器学习系统的开发做出贡献的作者的国籍。
系统
图1.2.3显示了来自特定国家的研究人员的重要机器学习系统的总数。一名研究人员被认为属于其机构的总部国家,例如大学或人工智能研究公司。2022年,美国生产了最多的重要机器学习系统,有16个,其次是英国(8)和中国(3)。此外,自2002年以来,就所生产的重要机器学习系统的总数而言,美国已经超过了英国、欧盟以及中国(图1.2.4)。图1.2.5显示了自2002年以来各国为全世界生产的重要机器学习系统的总数。
2022年按国家划分的重要机器学习系统的数量
(资料来源: Epoch和AI指数,2022年|图表: 2023年AI指数报告)
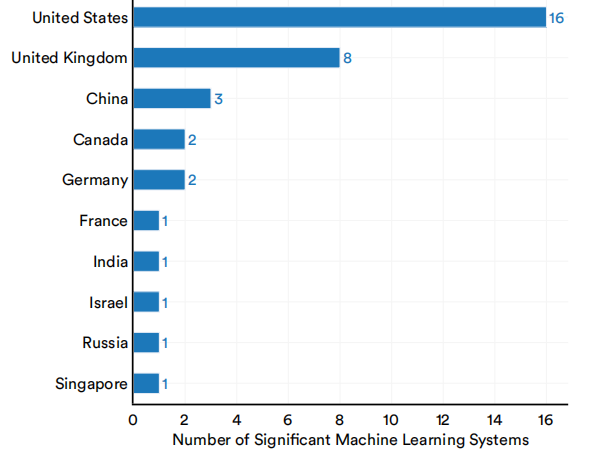
图1.2.3
2002-2022按选择的地理区域划分的重要机器学习系统的数量
(资料来源: Epoch和AI指数,2022年|图表: 2023年AI指数报告)
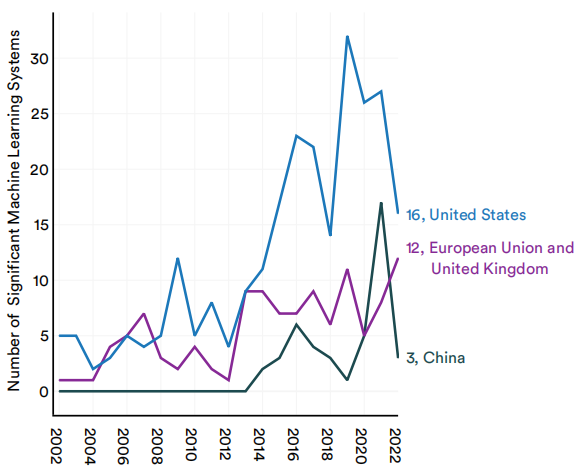
图1.2.4
2002-22年按国家划分的机器学习系统数量(总和)
(资料来源: Epoch和AI指数,2022年|图表: 2023年AI指数报告)
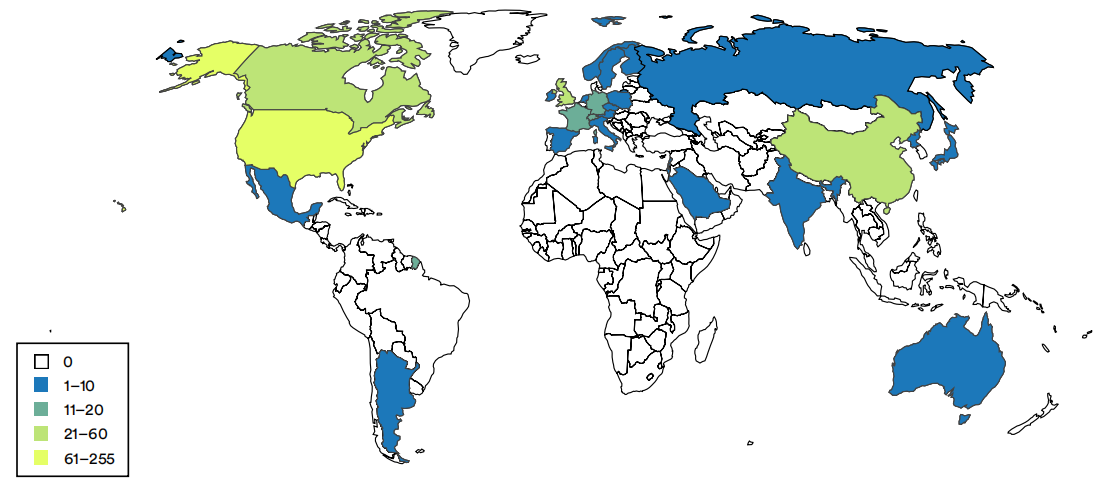
图1.2.5
归属
图1.2.6到1.2.8查看按国家归属关系分类的帮助启动重要机器学习系统的作者总数。就像总系统的情况一样,在2022年,美国生产重要机器学习系统的作者数量最多,有285个,是英国的两倍多,是中国的近6倍(图1.2.6)。
2022年,按国家划分的重要机器学习系统的作者数量
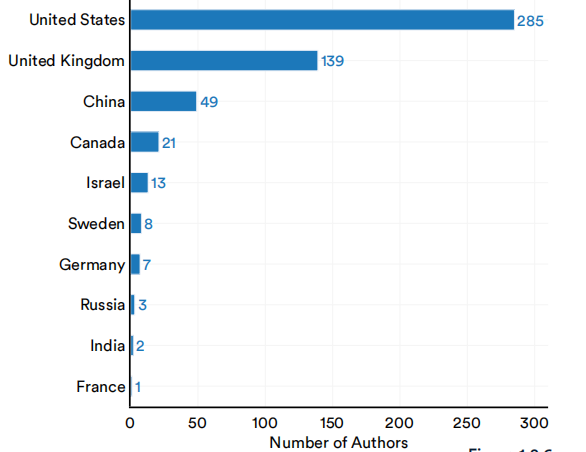
图1.2.6
2002-22年按选择的地理区域划分的重要机器学习系统的作者数量
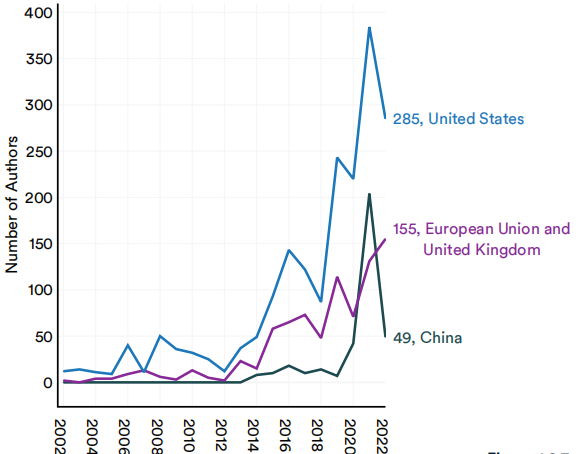
图1.2.7
2002-22年按国家划分的机器学习系统作者数量(总和)
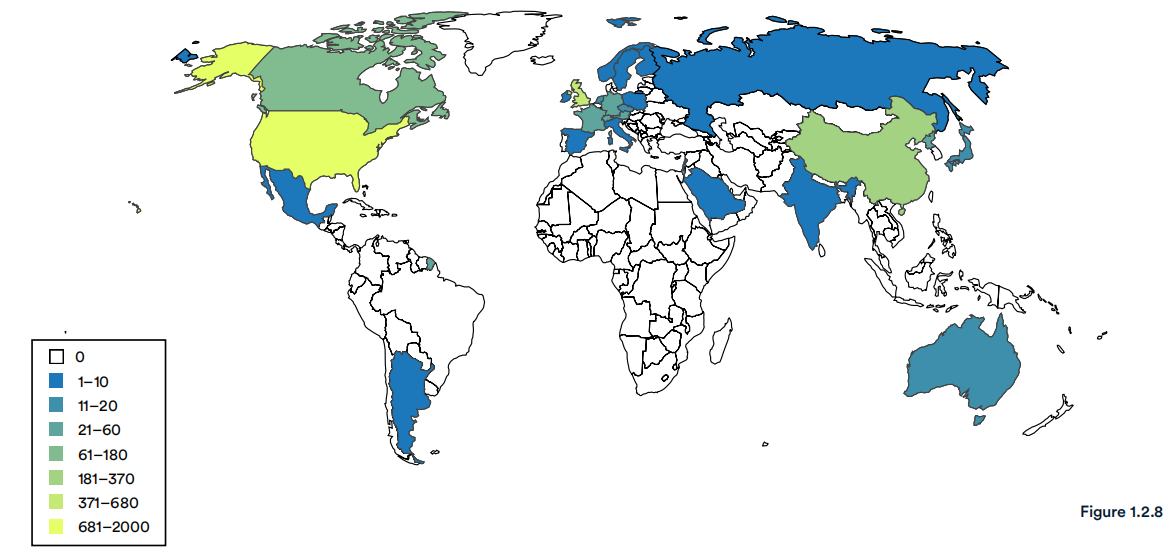
图1.2.8
参数趋势
参数是由机器学习模型在训练过程中学习到的数值。机器学习模型中的参数值决定了模型如何解释输入数据并做出预测。调整参数是确保机器学习系统的性能得到优化的一个必要步骤。图1.2.9按部门突出显示了Epoch数据集中包含的机器学习系统的参数数量。随着时间的推移,参数的数量一直在稳步增加,自2010年代初以来,这个增长尤为急剧。人工智能系统正在迅速增加其参数的事实反映了它们被要求执行的任务的复杂性增加,数据的可用性增加,底层硬件的进步,最重要的是,更大的模型的性能演示。
1950-22年按部门划分的重要机器学习系统的参数数量
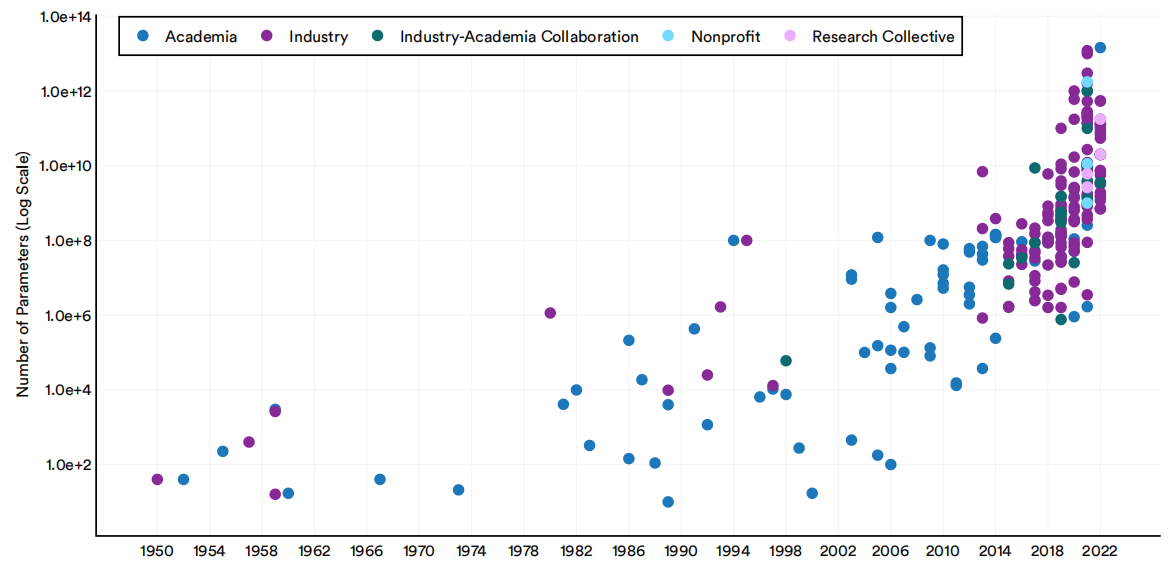
图1.2.9
图1.2.10按领域展示了机器学习系统的参数。近年来,参数丰富的系统数量不断增加。
1950-22年重要的机器学习系统按领域划分的参数数
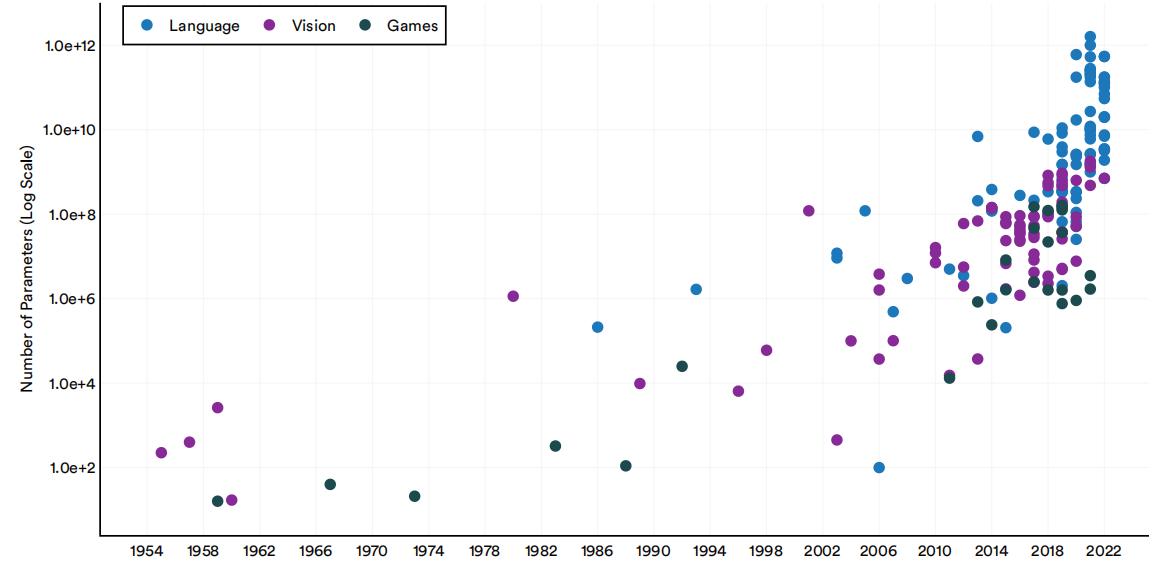
图1.2.10
计算趋势
人工智能系统的计算能力,或称“计算能力”,是指训练和运行机器学习系统所需的计算资源量。通常,一个系统越复杂,所训练它的数据集越大,所需的计算量就越大。在过去的五年里,重要的人工智能机器学习系统使用的计算量呈指数级增长(图1.2.11)。对人工智能计算需求的增长有几个重要的影响。例如,更密集型计算的模型往往对环境的影响更大,而工业参与者往往比大学等其他模型更容易获得计算资源。
1950-22年重要机器学习系统的分部门训练计算(FLOP)
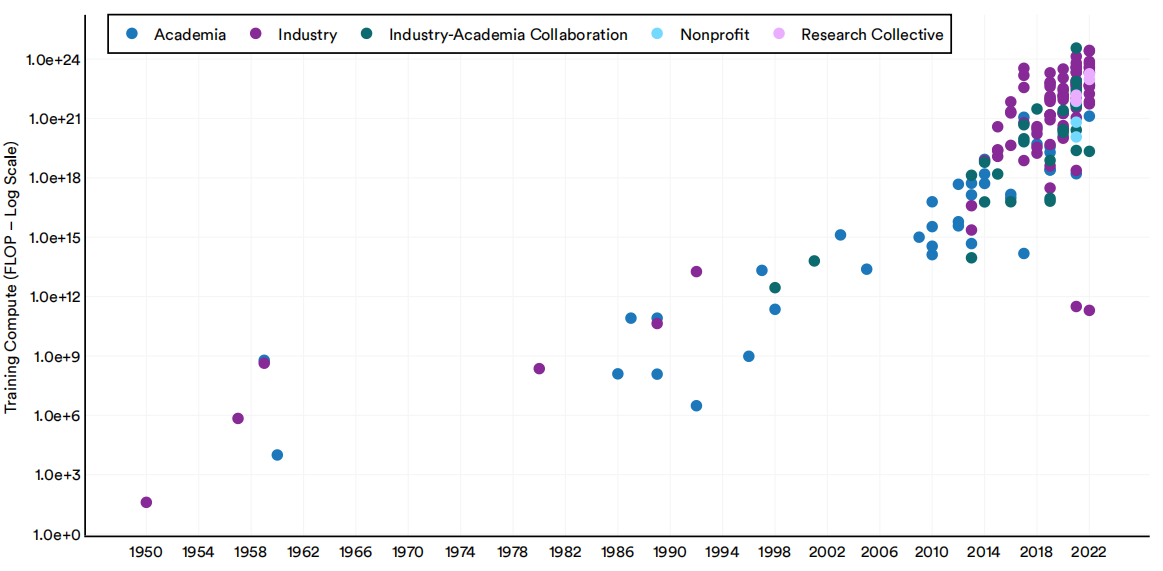
图1.2.11
自2010年以来,在所有的机器学习系统中,语言模型需要的计算资源越来越多。
1950-22年重要机器学习系统的分域训练计算(FLOP)
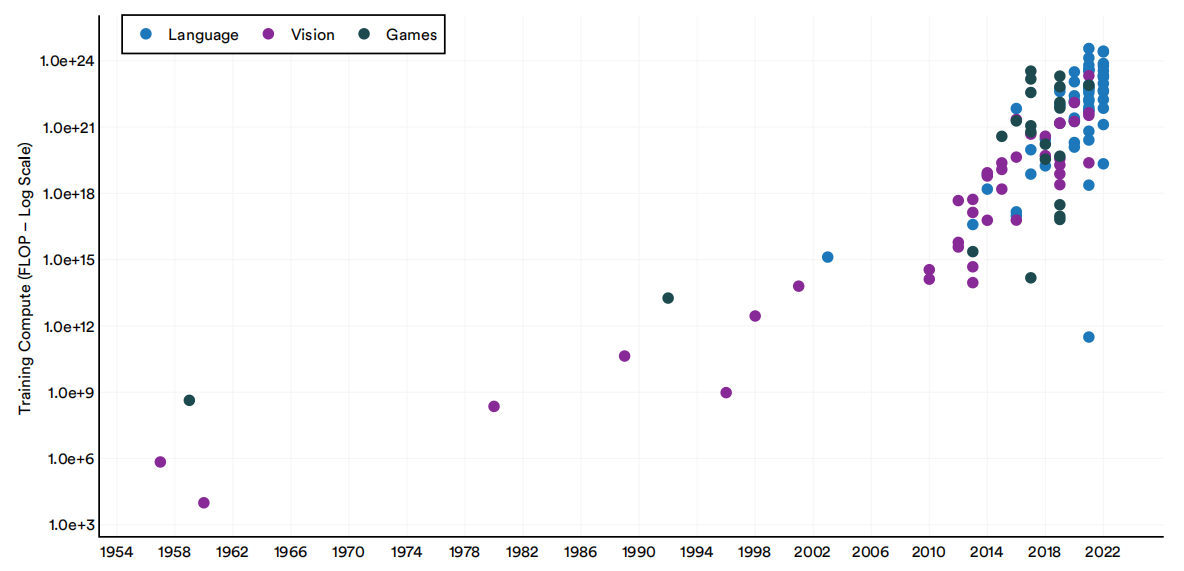
图1.2.12
大型语言和多模态模型
大型语言和多模态模型,有时被称为基础模型,是一种新兴的、日益流行的人工智能模型,它对大量数据进行训练,并适应各种下游应用程序。像ChatGPT、DALL-E 2和MakeA-Video这样的大型语言和多模态模型-Video模型已经展示了令人印象深刻的能力,并开始在现实世界中广泛应用。今年,人工智能指数对负责发布新的大型语言和多模态模型的作者的国家隶属关系进行了分析。10这些研究人员中的大多数来自美国的研究机构(54.2%)(图1.2.13)。2022年,来自加拿大、德国和印度的研究人员首次为大型语言和多模式模型的发展做出了贡献。
2019-22年按国家选择大型语言和多模态模型(占总数的%)的作者
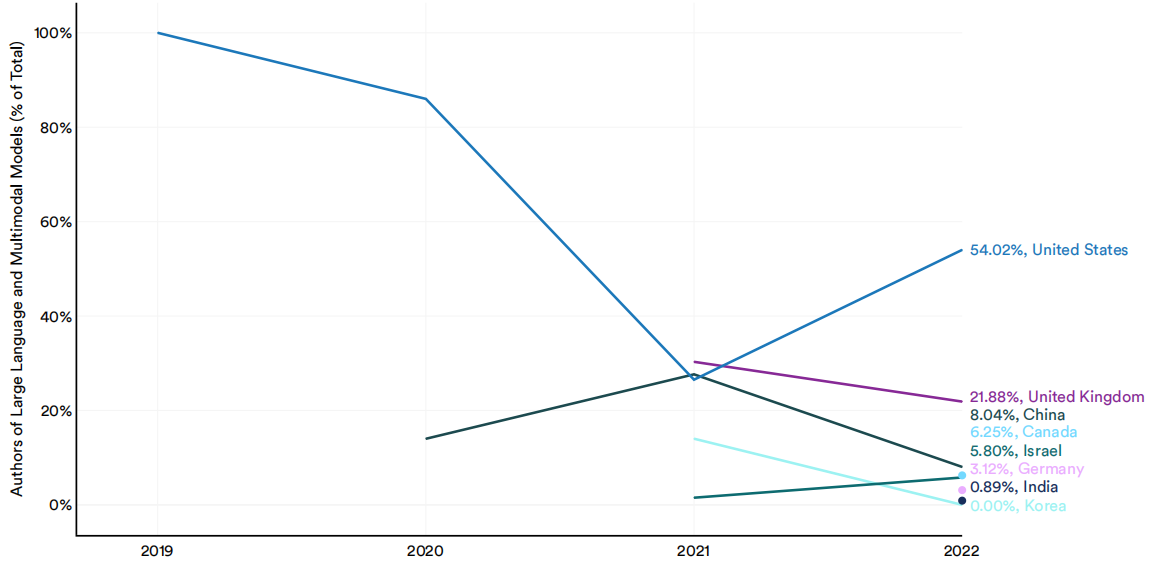
图1.2.13
图1.2.14提供了自GPT-2以来发布的大型语言和多模态模型的时间轴视图,以及产生这些模型的研究人员的国家附属机构。2022年发布的一些著名的美国大型语言和多模态模型包括OpenAI的DALL-E 2和谷歌的PaLM(540B)。2022年发布的唯一一种中国大型语言和多模式模式是GLM-130B,这是清华大学的研究人员创建的一种令人印象深刻的双语(英语和中文)模式。同样于2022年底推出的布鲁姆计划,由于它是1000多名国际研究人员合作的结果,因此被列为不确定计划。
选择大型语言和多语言模式模型发布的时间轴和国家归属
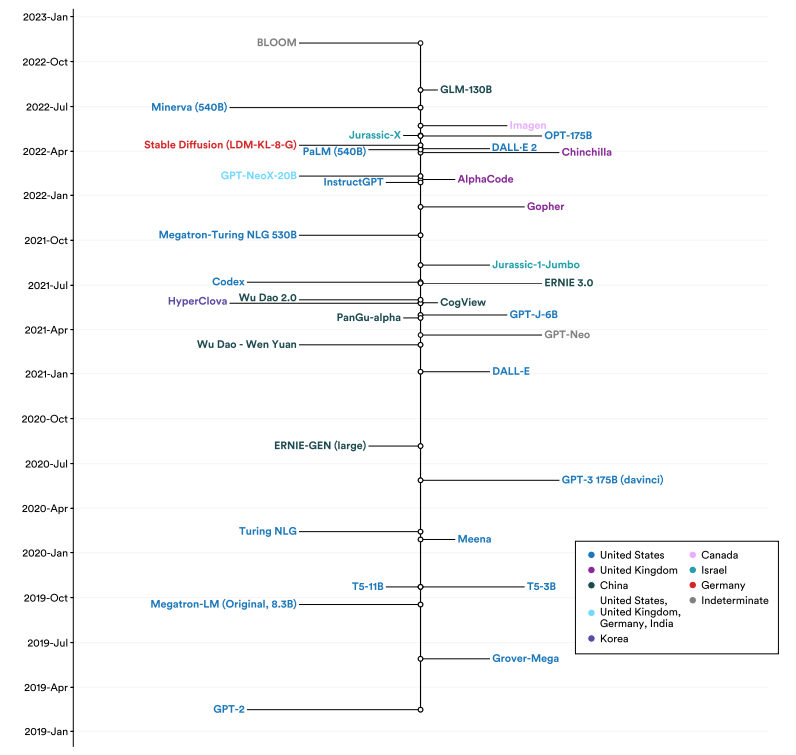
图1.2.14
参数计数
随着时间的推移,新发布的大型语言和多模态模型的参数数量大幅增加。例如,GPT-2是2019年发布的第一个大型语言和多模式模型,它只有15亿个参数。由谷歌于2022年推出的PaLM拥有5400亿美元,是GPT-2的近360倍。在大型语言和多模态模型中,参数的中位数随着时间的推移呈指数级增长(图1.2.15)。
2019-22年选择大型语言和多模态模型的参数数
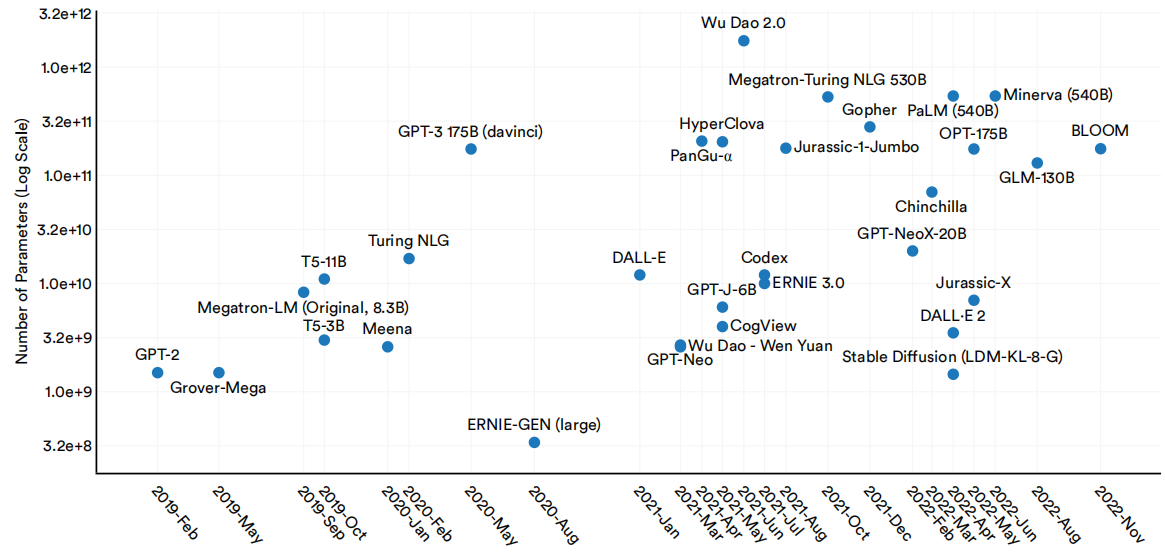
图1.2.15
培训计算
大型语言和多模态模型的训练计算量也在稳步增加(图1.2.16)。用于训练Minerva(540B)的计算量大约是OpenAI的GPT-3(2022年6月发布)的9倍,是GPT-2(2019年2月发布)的1839倍。Minerva是谷歌于2022年6月发布的一个大型语言和多模模型,在定量推理问题上表现出了令人印象深刻的能力。
2019-22年选择大型语言和多模态模型的训练计算(FLOP)
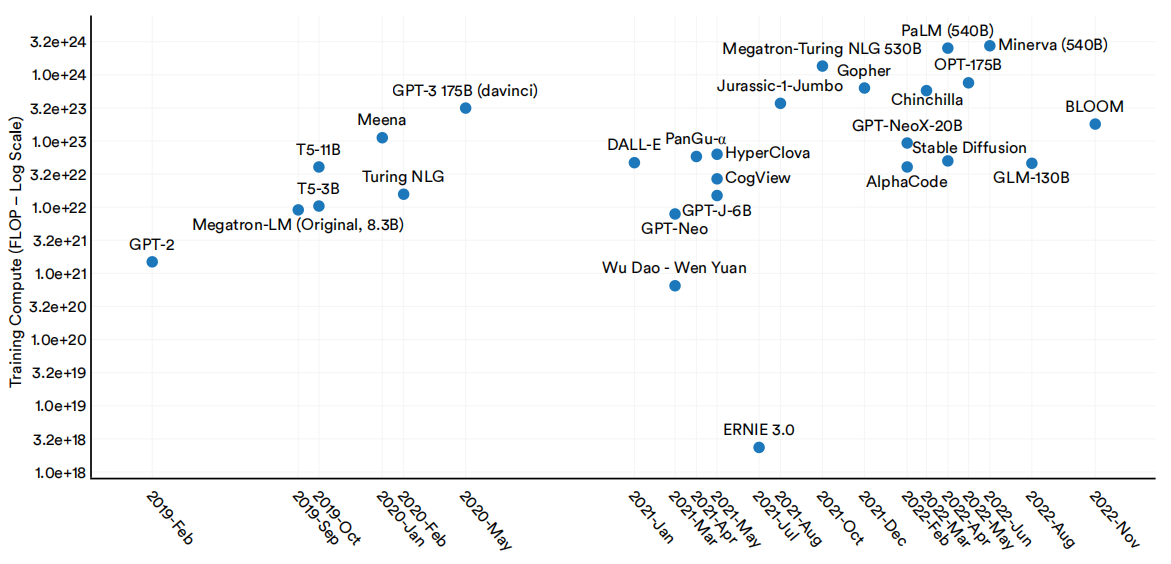
图1.2.16
训练费用
围绕大型语言和多模态模型的话语的一个特殊主题与它们的假设成本有关。尽管人工智能公司很少公开谈论训练成本,但人们普遍猜测,这些模型的训练成本为数百万美元,而且随着规模的扩大,成本将变得越来越昂贵。本小节介绍了一种新的分析,其中人工智能索引研究团队对各种大型语言和多模态模型的训练成本进行了估计(图1.2.17)。这些估计是基于模型的作者所披露的硬件和训练时间。在没有透露训练时间的情况下,我们根据硬件速度、训练计算和硬件利用率效率进行计算。考虑到估计值的可能可变性,我们用中、高或低的标签来限定每个估计值:中估计值被认为是中级估计值,高被认为是高估估计值,低被认为是低估估计值。在某些情况下,没有足够的数据来估计特定的大型语言和多模态模型的训练成本,因此这些模型在我们的分析中被省略了。
选择大型语言和多模态模型的估计训练成本
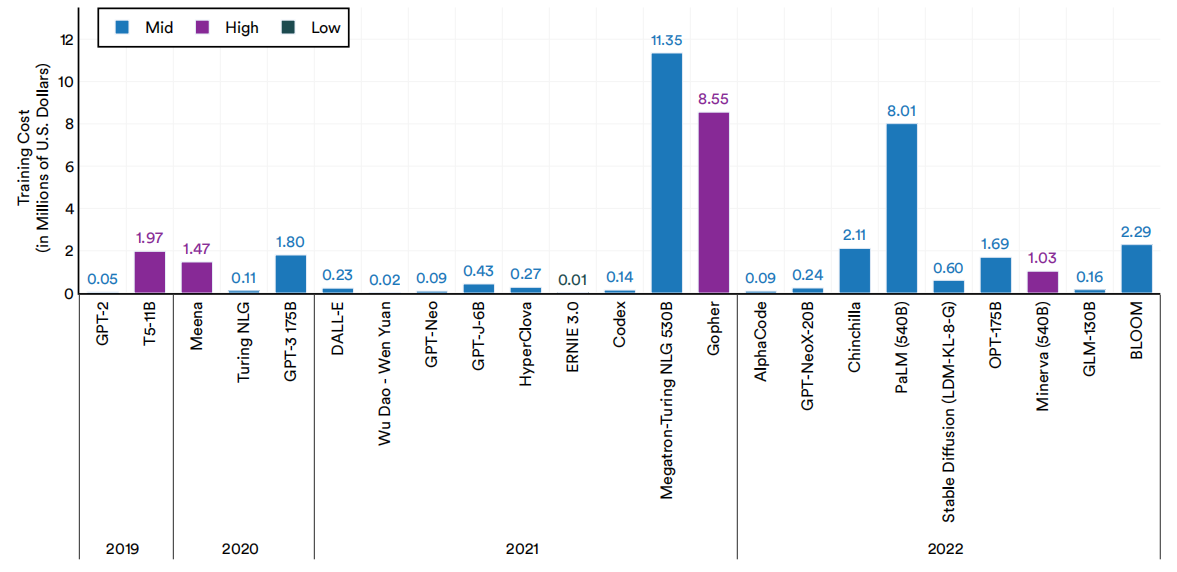
图1.2.17
大型语言和多模态模型的成本与其规模之间也有明显的关系。如图1.2.18和1.2.19所示,具有更多参数的大型语言和多模态模型以及使用大量计算的训练往往更昂贵。
选择大型语言和多模态模型的估计训练成本和参数数
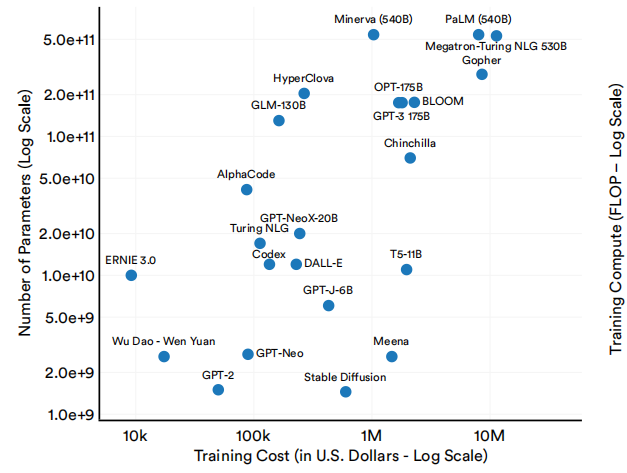
图1.2.18
选择大型语言和多模态模型的估计训练成本及训练计算(FLOP)
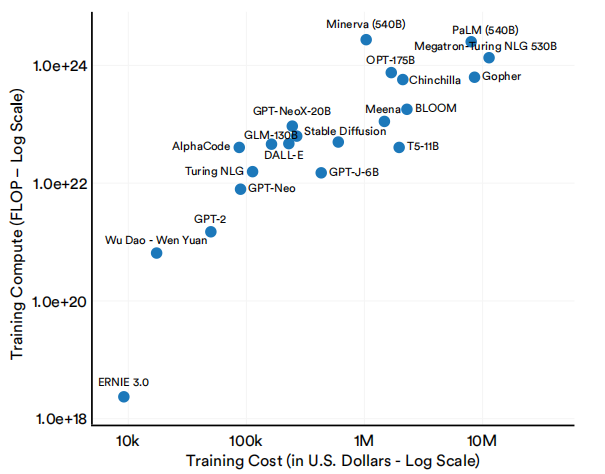
图1.2.19
人工智能会议是研究人员分享其工作、与同行和合作者建立联系的关键场所。出席会议表明了人们对一个科学领域的更广泛的工业和学术兴趣。在过去的20年里,人工智能会议的规模、数量和声望都有所增长。本节介绍了参加主要人工智能会议的趋势数据。